




El contexto actual: entornos de datos hiperdistribuidos
Hoy día, la velocidad de creación y consumo de datos por parte de las organizaciones está creciendo de forma muy significativa con la digitalización de sus negocios y transformación de sus aplicativos, la adopción de técnicas de Inteligencia Artificial generativa para la creación de contenido original a partir de datos ya existentes, y la explosión del cloud como su habilitador principal. Esta tendencia está provocando además un cambio en el valor que los datos tienen para una organización y la percepción que éstas tenían al respecto.
Pero esta agilidad en el uso y el valor de los datos está incrementando la superficie de ataque y complejidad para las organizaciones. Esto se debe a que los datos ya no se crean, consumen ni residen en perímetros (ubicaciones) más o menos predefinidos, sino en entornos hiperdistribuidos: múltiples CSPs, aplicativos SaaS, servicios de data lake, etc. En este contexto, las estrategias de protección de datos –que todavía en muchos casos se centran mayoritariamente en la protección de los aplicativos, la red e infraestructuras donde estos se alojan y procesan– dejan de ser válidas precisamente por esa dilución del concepto de perímetro, así como esa necesidad de una mayor agilidad de adecuación y adaptación al cambio.
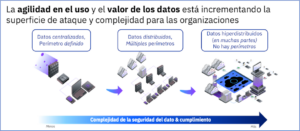
Esta nueva realidad demanda una redefinición y evolución de nuestra estrategia para potenciar y poner un mayor foco en la protección del dato en sí, poniéndolo en primer lugar y en una posición central de la estrategia (data-centric protection), en lugar de únicamente en la infraestructura donde está alojado.
Pero, una vez revisitada la estrategia, pueden surgir dudas respecto a cómo implementarla.
Las aproximaciones y tecnologías existentes, ¿una sopa de letras?
Para poder dar respuesta a las necesidades de protección del dato existen numerosas soluciones disponibles en el mercado, que continuamente escuchamos por sus siglas en inglés: bDSP y DSP, DSaaS, CASB, DLP, EKM, KMaaS, FHE, DAG, DSG, confidential computing (en TEEs/enclaves), etc.
Esta sopa de letras de soluciones supone un problema para muchas empresas que no son capaces de determinar qué es lo que necesitan y cómo priorizarlo, no sólo por su elevado número (por ejemplo, Gartner enumera más de 30 en Hype Cycle for Data Security 2022) sino por la necesidad de disponer de conocimientos avanzados y especialistas en la materia.
Ante esta encrucijada, lo fundamental es saber posicionar dicha tecnología en el contexto de nuestra estrategia de protección y cómo contribuye a ella, es decir:
- Qué casos de uso resuelve (funcionalidad proporcionada) para entender qué tecnologías o soluciones son análogas, pues sirven para implementar el mismo control de seguridad.
- Sobre qué fases de nuestra estrategia actúa (conocimiento de los datos, protección, monitorización, respuesta/remediación, visibilidad/gobierno, etc.)
- Sobre qué tipo de datos/información y de activos actúa (ej: estructurada, no estructurada, cloud vs. onprem, etc.)
- Por último, y a partir de todo lo anterior, qué riesgos realmente mitiga/elimina de los que específicamente he identificado sobre mis datos.
Pero, aunque estas soluciones resuelven bien (o muy bien) el objetivo que persiguen, el principal problema que presentan es que generalmente se centran en el plano operativo resolviendo sólo casos de uso de protección concretos. Además, funcionan como silos independientes, son eminentemente estáticas y no tienen en cuenta aspectos fundamentales para la protección como la sensibilidad, el linaje y residencia de los datos (ubicación, formato…), la configuración de la infraestructura o la agilidad de gestión y adaptación que requiere el cloud.
En definitiva, no son capaces de proporcionar una visión holística, completa y dinámica de todos los aspectos relativos a la postura de seguridad de los datos, incluyendo una vista común del mapa de riesgos, y su priorización a partir del contexto, la sensibilidad, el linaje, la exposición y el uso de estos.
Los controles nativos proporcionados por los CSPs
También es frecuente encontrar que muchas organizaciones directamente abogan por el uso de las capacidades y controles nativos que proporcionan los CSPs para la protección de sus datos. En realidad, no dejan de ser implementaciones de alguna de las categorías descritas anteriormente y, por ello, a priori no añaden nada nuevo.
La decisión de utilizarlos como opción preferente se debe por lo general a su agilidad para poder ser consumidos de forma directa. Y, a su vez, presentan modelos de pago por uso inicialmente atractivos, y sin tener que realizar un desembolso inicial, por ejemplo, en concepto de licencias.
Sin embargo, aunque en general estos controles pueden ser efectivos en la nube del CSP que los proporciona, en la práctica tienen poca o nula interoperabilidad e integración con el resto de clouds y/o con herramientas de protección de datos de terceros. Esto supone un inconveniente adicional, pues obliga a que la organización realice una gestión de los riesgos y gobierno de la estrategia de protección de forma aislada para cada uno de los hyperscalers.
La revolución del Data Security Posture Management (DSPM)
Para dar respuesta a esta necesidad de mayor visibilidad y poder monitorizar en tiempo real todo lo que afecta a la postura de seguridad de los datos, incluyendo el gobierno consistente de los riesgos a través de diferentes CSPs, y de la forma más automatizada posible, en los últimos años ha surgido una nueva categoría de soluciones denominada Data Security Posture Management (DSPM).
Este concepto fue introducido por Gartner por primera vez en su informe Hype Cycle for Data Security 2022 como una de las principales tecnologías emergentes que “proporciona visibilidad sobre dónde residen los datos sensibles, quién tiene acceso a esos datos, cómo se han utilizado y cuál es la postura de seguridad del repositorio o el aplicativo que los usa”.
Dicho de forma sencilla y como la propia Gartner refleja en informes posteriores, la soluciones DSPM brindan «descubrimiento de datos avanzado», es decir, descubrimiento en profundidad junto con características de “observabilidad” de los datos. Estas funcionalidades pueden incluir visibilidad en tiempo real de los flujos de datos, y el nivel de riesgo y cumplimiento a partir de los controles de seguridad aplicados. El objetivo es identificar gaps de seguridad y exposiciones indebidas. DSPM acelera el análisis de cómo se puede reforzar y hacer cumplir la postura de seguridad de los datos a través de controles de seguridad complementarios.
Aunque el DSPM surgió inicialmente de la mano de nuevas empresas, lo cierto es que existe una tendencia a que fabricantes ya consolidados comiencen a integrar en su portfolio este conjunto de funcionalidades Por ello quizás es más preciso hablar de capacidades de DSPM que de tecnologías/productos en sí mismos como una solución independiente.
Principales beneficios y características de un DSPM
Los principales casos de uso y beneficios de un DSPM se pueden clasificar en:
- Descubrimiento de datos críticos (estructurados y no estructurados): incluyendo repositorios y bases de datos no utilizadas o desconocidas (shadow data) y clasificación de dichos datos en función de su tipología, sensibilidad, contexto, flujos, y relación/mapeo con normativas aplicables.
- Detección de riesgos y amenazas sobre los datos en función de su sensibilidad y nivel de exposición, así como su priorización para determinar cuáles deben ser mitigados antes. Para ello, se deben entender los flujos de creación, uso y consumo de los datos (linaje), qué/quién tiene acceso o accedió a los mismos, e incluso sus configuraciones/vulnerabilidades. Algunos ejemplos de riesgos habituales que un DSPM ayuda a descubrir son, por ejemplo, los relativos a:
- Un inadecuado gobierno de los accesos a los datos. Por ejemplo, eliminando aquellos que están accesibles públicamente en CSPs y aplicativos SaaS, o que tienen una excesiva exposición a terceros (subcontratista, proveedores, etc.)
- Movimientos indeseados o desconocidos de los datos, por ejemplo, entre entornos y/o cuentas de la organización (puede suponer cambios en su nivel de protección, exposición o acceso por terceros), entre regiones/países (modifican la residencia de los datos, lo cual suele ser relevante para el cumplimiento), hacia componentes y/o aplicativos no permitidos, etc.
- La pérdida o fuga de datos desde mis entornos cloud, aplicativos SaaS y/o servicios de data lake.
- Soporte para la respuesta y remediación de las vulnerabilidades y riesgos identificados, además de proponiendo medidas para que no vuelvan a ocurrir.
Por otra parte, los DSPM presentan las siguientes características:
- Una alta automatización de los procesos DSPM descritos anteriormente: evaluación de la postura de seguridad de los datos, descubrimiento y priorización de riesgos/vulnerabilidades y su remediación. De hecho, si la solución no es capaz de hacerlo lo más automáticamente posible, impide su objetivo de implementar protección en los CSPs a escala masiva. Los diferentes fabricantes son conscientes y están poniendo mucho foco en el desarrollo de capacidades que habiliten esta automatización; por ejemplo, aumentando los “clasificadores automáticos” de datos out-of-the-box, incorporando y mejorando los algoritmos de proximidad y el uso de AI/ML para aumentar la precisión del análisis contextual, etc.
- Son agent-less, es decir, no requiere el despliegue de agentes y trabajan a nivel de CSP, aplicativo SaaS o servicio de data lake (no de base de datos o repositorio de ficheros), utilizando las APIs nativas que éstos proporcionan para su implantación, lo que hace que sea muy poco intrusivo y agiliza considerablemente su despliegue. Igualmente, un DSPM proporciona 100% acceso vía API para integrarse fácilmente con otras herramientas de protección de datos existentes en la organización.
Por último, cabe mencionar que los DSPM no pretenden reemplazar otras herramientas existentes de seguridad de los datos o para la gestión y mejora de la postura de seguridad en otros ámbitos (ej: de las aplicaciones o ASPM, del cloud o CSPM, etc.). El objetivo es que se complementen y trabajen conjuntamente. De hecho, los DSPM deberían incorporar datos contextuales, alertas y otras métricas de la infraestructura, herramientas de seguridad, operaciones TIC y DevSecOps existentes.
Conclusión
Para mantener los datos críticos de nuestra organización adecuadamente protegidos se requiere gestionar los riesgos a los que se ven sometidos, así como reducir su nivel de exposición aplicando los principios de “necesidad de conocer” y de “necesidad de compartir”. Para ello, es importante “entender” qué datos se utilizan (tipología, sensibilidad, contexto…), dónde residen (repositorios estructurados y no estructurados, residencia…) y quién los utiliza (accesos, exposición, flujos…). Y esta visibilidad sobre la postura de seguridad de los datos y su gestión debe ser estática y en tiempo real.
Las capacidades de Data Security Posture Management (DSPM) suponen un nuevo paradigma que ponen al dato en primer lugar y en una posición central, para proporcionar una visión holística e integrada de todo lo que afecta a la postura de seguridad de los datos. Los DSPM combinan funciones de descubrimiento, monitorización y análisis de la información en tiempo real, una vista común del mapa de riesgos, y su priorización a partir del contexto, sensibilidad, linaje, exposición y uso de los datos. Aunque son tecnologías relativamente novedosas, sus características poco intrusivas y facilidad de despliegue hacen que tengan unos tiempos de despliegue y time-to-value relativamente cortos y una dependencia baja del fabricante seleccionado, lo que las hace relativamente atractivas para cualquier organización.
Juan Carlos de Miguel Pérez-Herce, Cibersecurity Services, IBM Consulting










